An exchange rate (XR) is the rate at which one currency will be exchanged for another currency, and thus XRs are used in everything related to trades, several processes in Finance relying on them. There are various sources for the XR like the European Central Bank (ECB) that provide the row data and various analyses including graphical representations varying in complexity. Conversely, XRs' processing offers some opportunities for learning techniques for data visualization.
On ECB there are monthly, yearly, daily and biannually XRs from EUR to the various currencies which by triangulation allow to create XRs for any of the currencies involved. If N currencies are involved for one time unit in the process (e.g. N-1 XRs) , the triangulation generates NxN values for only one time division, the result being tedious to navigate. A matrix like the one below facilitates identifying the value between any of the currencies:

Moreover, for some operations is enough to work with two decimals, while for others one needs to use up to 6 or even more decimals for each XR. Occasionally, one can compromise and use 3 decimals, which should be enough for most of the scenarios. Making sense of such numbers is not easy for most of us, especially when is needed to compare at first sight values across multiple columns. Summary tables can help:

Statistics like Min. (minimum), Max. (maximum), Max. - Min. (range), Avg. (average) or even StdDev. (standard deviation) can provide some basis for further analysis, while sparklines are ideal for showing trends over a time interval (e.g. months).
Usually, a heatmap helps to some degree to navigate the data, especially when there's a plot associated with it:

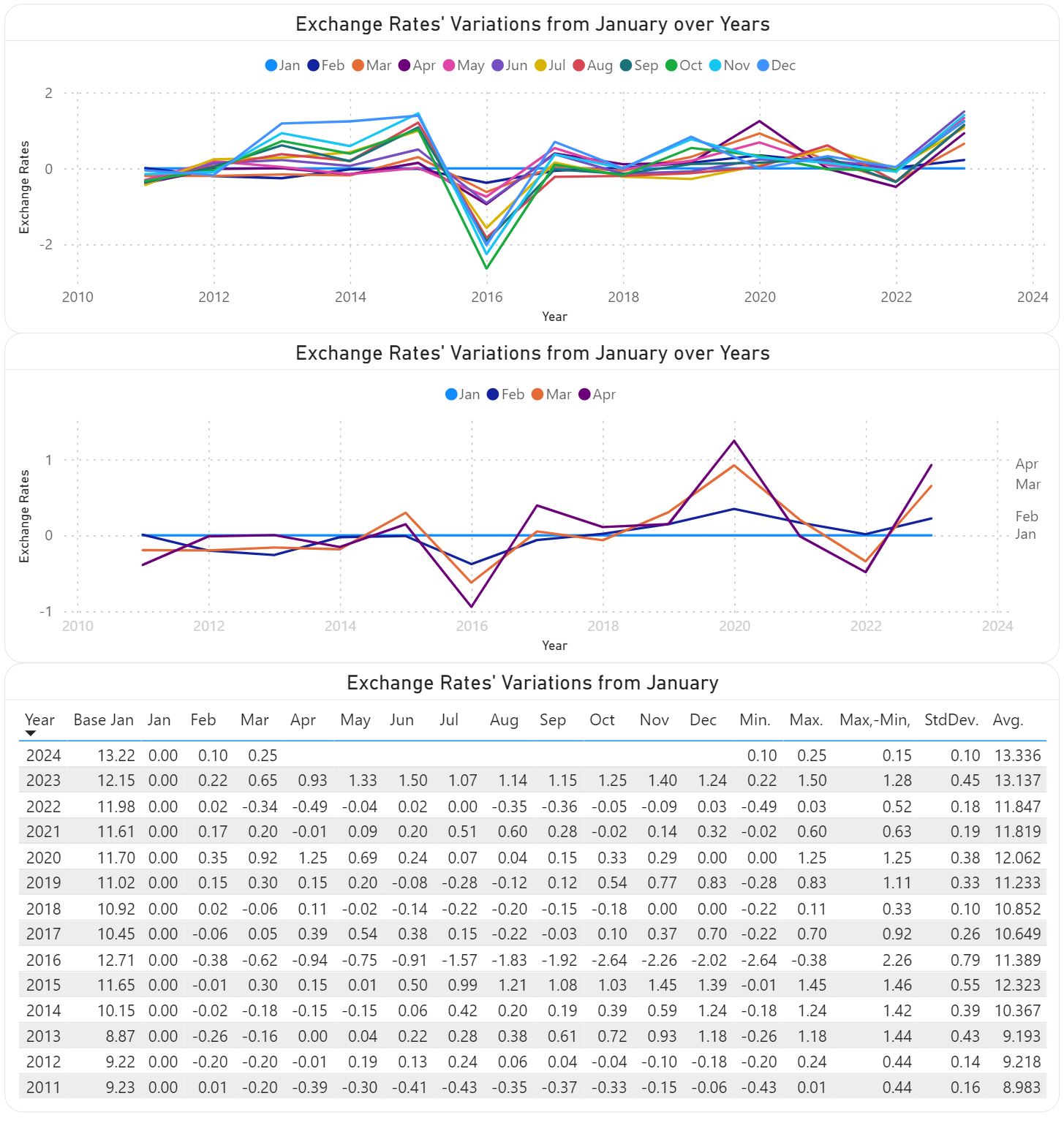





Comments:
1) I used GBP to NOK XRs to provide an example based on triangulation.
2) Some experts advise against using borders or grid lines. Borders, as the name indicates allow to delimitate between various areas, while grid lines allow to make comparisons within a section without needing to sway between broader areas, adding thus precision to our senses-making. Choosing grey as color for the elements from the background minimizes the overhead for coping with more information while allowing to better use the available space.
3) Trend lines are recommended where the number of points is relatively small and only one series is involved, though, as always, there are exceptions too.
4) In heatmaps one can use a gradient between two colors to show the tendencies of moving toward an extreme or another. One should avoid colors like red or green.
5) Ideally, a color should be used for only one encoding (e.g. one color for the same month across all graphics), though the more elements need to be encoded, the more difficult it becomes to respect this rule. The above graphics might slightly deviate from this as the purpose is to show a representation technique.
6) In some graphics the XRs are displayed only with two decimals because currently the technique used (visual calculations) doesn't support formatting.
7) All the above graphical elements are based on a Power BI solution. Unfortunately, the tool has its representational limitations, especially when one wants to add additional information into the plots.
8) Unfortunately, the daily XR values are not easily available from the same source. There are special scenarios for which a daily, hourly or even minute-based analysis is needed.
9) It's a good idea to validate the results against the similar results available on the web (see the ECB website).
Previous Post <<||>> Next Post